

An Efficient Parallelism
rhombus is a generalizable python-mpi utility for task-based parallel programming.
Theory
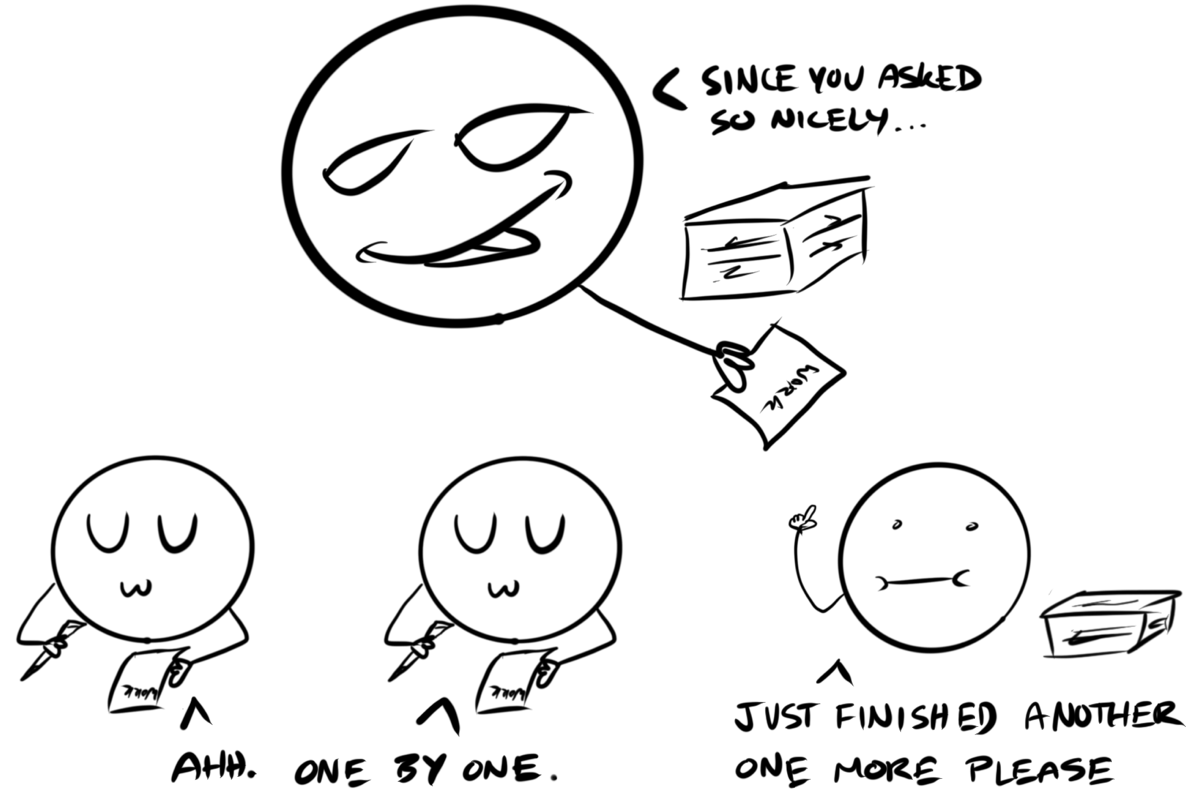
This implementation of task-based parallel programming consists of one root processor, and any number of worker processors. The root breaks a portion of a job into bite sized chunks (like a single file) which are then sent to the workers. While the workers... well... work, the root sits and waits. When a worker finishes with its allotted chunk, it pings the root node and asks for another chunk, which the root node then provides. Therefore no worker is ever left without something to do.
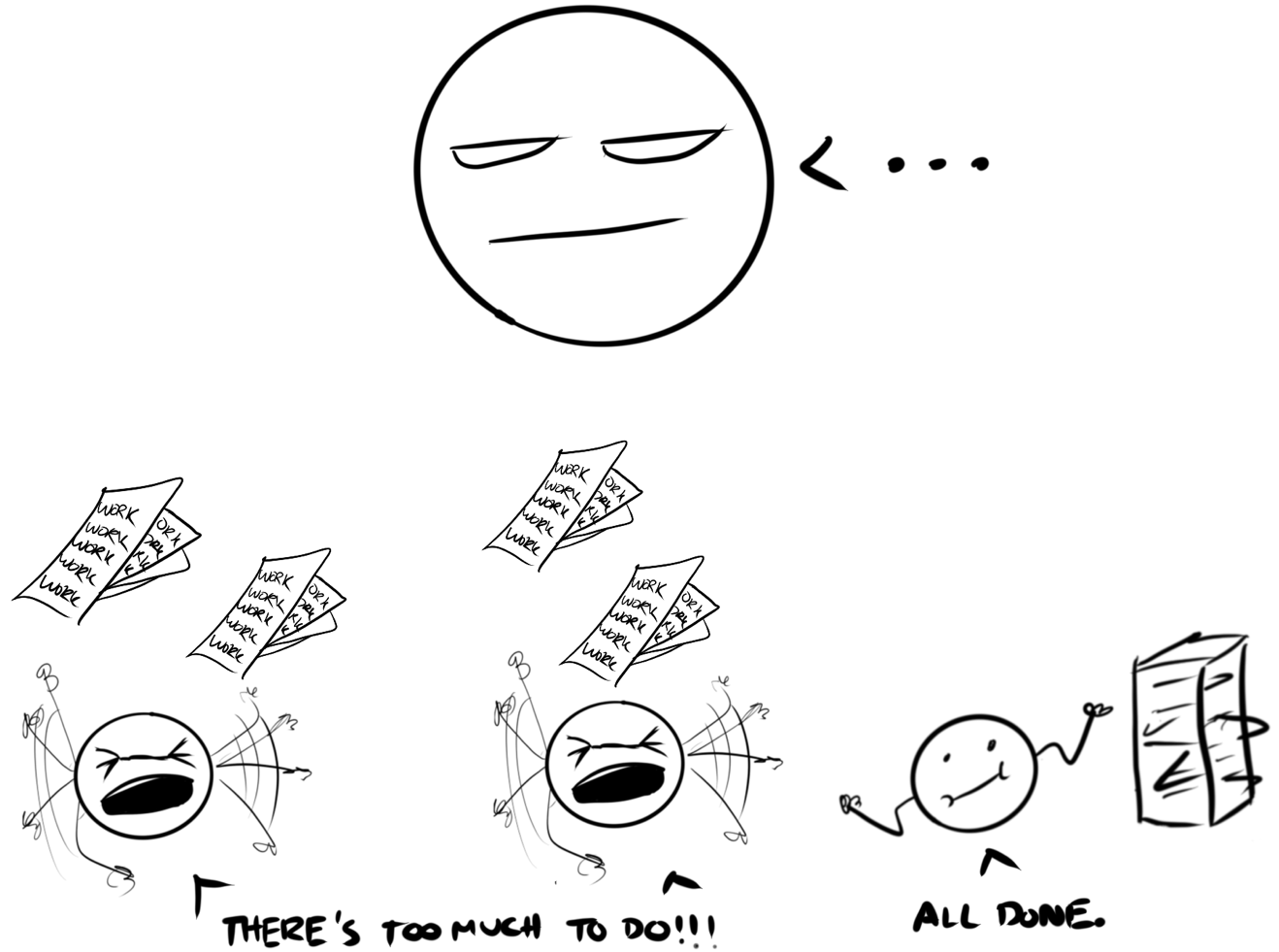
This is fundamentally different and more efficient than data-based parallel processing in which an entire job is split into n equally sized chunks (where n is the number of processors) and sent to the worker processors. In this method, when a worker is done processing, it does not need to ask the root node for any more work (since everything has already been distributed to the workers). Therefore, although the task is being completed in parallel, there is a chance that workers will be left idle while they wait for other workers to finish.
Requirements
In addition to whichever packages you use for your process you wish to parallelize, you will need to ensure you have working installs of the following:
- python v3.X
- OpenMPI v4.X.X
- mpi4py python library
Ensure you have a properly configured and installed version of OpenMPI with your PATH and PYTHONPATH correctly pointed to the install directory before attempting to pip install mpi4py.
For your consideration

In principle task-based parallelism is the more efficient method of parallel programming though with the caveat that any efficiency increase over data-based parallelism tends to zero the more uniform the processing requirements for work chunks. I originally wrote rhombus to aid in the processing of data from astrophysical simulations of star formation, but it is generalizable to any processing tasks that can be strategically chunked.
rhombus has been used used by and interfaces with software from at least three research groups on several supercomputing clusters. Over 20 Terabytes of data have flowed through rhombus. My tool is free and open for anyone to use in any capacity. — Github
I've provided several examples of uses for this type of parallelism. Multiprocessing of files is the most intuitive (at least to me). You can also reduce arrays across processes in-place in which each processor will build a (5,) numpy array with index [I] == I, where I is the unique processor rank (e.g. processor 2 will make [0 0 2 0 0]). Then, the root processor will collect all of the arrays and perform the MPI.SUM operation on them. The result (if using 4 processors) will be [0 1 2 3 4]. The MPI.SUM operation can be replaced with any other MPI op code. Similarly, you can reduce a dictionary in-place where each processor is given an empty dictionary and will insert a single key/value pair of str(rank):rank*100 (e.g. processor 2 dictionary is {'2':200}). The root processor then gathers all dictionaries from all processors and updates its own dictionary with the unique pairs.
Note that this method of parallelism also works across multiple nodes of many processors (applicable to most if not all supercomputers) but in those cases you would also need to provide a hostfile to define which processors across the nodes are to be used.
I've joked that the true form of enlightenment when it comes to rhombus is realizing that the parallizable task can be any function, with any number of input args and kwargs. If your task can be condensed into a single function with a discrete amount of input work, it can be parallelized with this routine. Indeed it is quite powerful for such as simple python wrapper.